#
005 - Federated Architecture

Last Modified: Nov 9th, 2025
Status: Accepted
#
Context
Ricoh’s Intelligent Business Platform (IBP) has reached a point where the existing psuedo-microservice approach hinders scalability, agility, and resilience. The platform has grown brittle, making it difficult to release new features without risking platform-wide instability. Team autonomy is limited, and the release velocity has stalled due to tightly coupled dependencies and shared infrastructure. To unlock scalability, reduce coordination overhead, and support a modern digital services roadmap, a new architecture strategy is required.
#
Decision
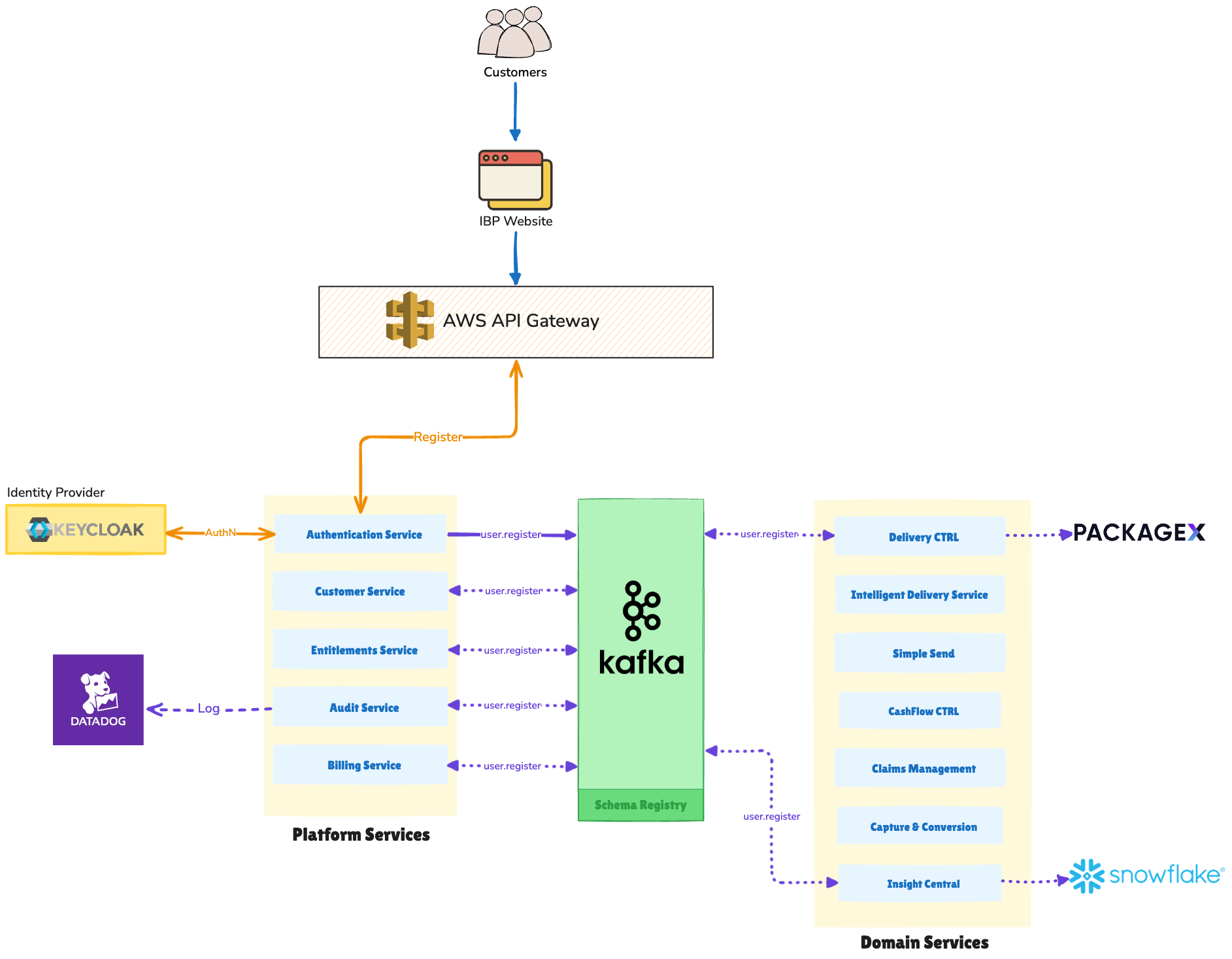
We will adopt a federated modular architecture. What we are dubbing as IBP Next, consisting of the following core components:
Event-Driven Backbone: Apache Kafka serves as the primary communication mechanism between services, enabling asynchronous, distributed event processing with high throughput and fault tolerance.
Platform-Level Shared Services: Centralized services that provide cross-cutting capabilities (e.g., Customer Service, Identity/Authentication, Audit Service) that multiple domain services depend upon. These services maintain shared domain models and data.
Domain-Aligned Product Services: Independently deployable services organized around business capabilities and bounded contexts (e.g., Delivery CTRL, Intelligent Delivery Service, Simple Send, CashFlow CTRL). Each service owns its domain data and business logic.
Centralized API Gateway: A single entry point (e.g., AWS Gateway or Kong) that handles routing, rate limiting, authentication, request transformation, and API versioning for all external-facing services.
Federated Identity: External Identity Provider (IdP) such as Keycloak or Auth0 manages authentication and authorization, enabling single sign-on (SSO) and centralized user management across all services.
Observability Stack: Comprehensive monitoring, logging, distributed tracing, and alerting infrastructure to support operational visibility across the distributed system using Cloudwatch or Datadog.
The term "federated" here refers to the organizational model where multiple autonomous teams own and operate their respective services while adhering to platform-wide standards and governance established by the Architecture team. This enables independent development and deployment velocity while maintaining architectural consistency and operational reliability.
#
Rationale
The decision is guided by architectural principles and practical needs:
Evolvability: Modular domain services aligned to bounded contexts enable low-coupling and easier incremental changes. Each service can evolve its data model, business logic, and technology stack independently without requiring coordinated changes across the entire platform. This allows teams to respond to changing business requirements more rapidly and reduces the risk of unintended side effects when making changes.
Scalability: Kafka's partitioned, distributed log model supports high-throughput communication between independently scaling services. Unlike synchronous request-reply patterns, event-driven communication allows services to process messages at their own pace, handle traffic spikes without blocking upstream services, and scale horizontally based on consumer group parallelism. This is critical for supporting IBP's growing transaction volumes and user base.
Fault Isolation: Services operate asynchronously through event streams, meaning failures in one service are contained and do not cascade to others. If a service goes down, other services can continue operating, and the failed service can process pending events when it recovers. This dramatically improves overall system resilience compared to tightly coupled synchronous systems where one failure can bring down the entire platform.
Team Autonomy: Product teams can develop, deploy, and own services independently, aligning with Inverse Conway's Maneuver (organizational structure mirrors system architecture). This reduces coordination overhead, enables faster feature delivery, and allows teams to optimize their development practices and technology choices within defined boundaries. Teams can release on their own cadence without waiting for platform-wide releases.
Alignment with Industry Best Practices: The architecture reflects recommendations from Designing Data-Intensive Applications (Kleppmann) regarding event sourcing, distributed systems patterns, and data consistency models, as well as Building Evolutionary Architectures (Ford/Parsons/Kua) on creating architectures that can evolve over time. This approach is battle-tested at scale by organizations facing similar challenges.
#
Governance Model
The federated architecture requires a clear RACI (Responsible, Accountable, Consulted, Informed) framework to maintain autonomy without chaos. This governance model ensures that teams have clear boundaries, accountability, and decision-making authority while maintaining platform-wide consistency and quality standards.
#
Team Roles and Responsibilities
Architecture Team (Accountable): Defines platform standards, service design patterns, API contracts, event schemas, and compliance criteria. Monitors adherence and approves architectural changes. The Architecture team sets the "rules of the game" that all services must follow, conducts architecture reviews, and maintains reference implementations. They are the single source of truth for what constitutes acceptable architectural decisions.
Development Team (Responsible): Implements domain services following Architecture-defined standards. Maintains compliance and cannot change standards without Architecture approval. Development teams own the implementation, testing, and operational aspects of their services, but must work within the architectural boundaries and patterns established by the Architecture team. They are responsible for ensuring their services meet quality gates and operational requirements.
Infrastructure Team (Accountable for Ops): Owns CI/CD pipeline standards, infrastructure automation, monitoring, and operational tooling. Provides shared infrastructure capabilities, maintains deployment pipelines, and ensures platform-level observability and reliability. Development teams use Infrastructure-provided templates and tooling but cannot modify core infrastructure standards without Infrastructure approval.
Support Team (Responsible for Operations): Handles incident triage, monitoring, and first-line operational continuity. Provides 24/7 operational coverage, performs initial incident investigation, and escalates to Development or Infrastructure teams as needed. Support teams are responsible for maintaining operational runbooks and ensuring service-level agreements are met.
Agile Delivery Team (Coordinates): Manages release planning, deployment coordination, and cross-team delivery alignment. Ensures that multiple service deployments are coordinated when necessary, manages release calendars, and facilitates cross-team communication. They coordinate delivery activities but do not own the technical implementation or standards.
QA Team (Responsible, within Agile Delivery): Coordinates testing activities across services and facilitates quality assurance throughout the delivery lifecycle. Defines testing strategies and test environment requirements, coordinates cross-service integration testing, manages test data and environments, and validates release readiness. QA teams work with Development teams to ensure test coverage and quality gates are met, coordinate end-to-end testing for cross-service features, and facilitate test automation standards adoption. They coordinate testing activities but do not own the technical implementation (owned by Development) or testing standards (defined by Architecture in collaboration with QA).
Leadership Team (Strategic Accountability): Sets platform vision, approves major investments, and resolves cross-domain conflicts. Provides executive sponsorship, makes strategic decisions about platform direction, and resolves situations where Architecture and Development teams cannot reach consensus on architectural decisions.
#
Governance Principles
The governance model operates on several key principles:
- Clear Accountability: Each activity has exactly one Accountable party who makes final decisions and owns outcomes.
- Standards Compliance: Development teams must follow standards set by Architecture; they cannot unilaterally change standards but can propose changes through proper channels.
- Shared Responsibility for Security: All teams are responsible for security in their domain, with Leadership holding overall accountability.
- Autonomy Within Boundaries: Teams have autonomy to make implementation decisions within their service boundaries, but must adhere to platform standards at service boundaries (APIs, events, data contracts).
- Continuous Compliance Monitoring: Architecture team monitors compliance with standards and provides feedback loops to ensure ongoing adherence.
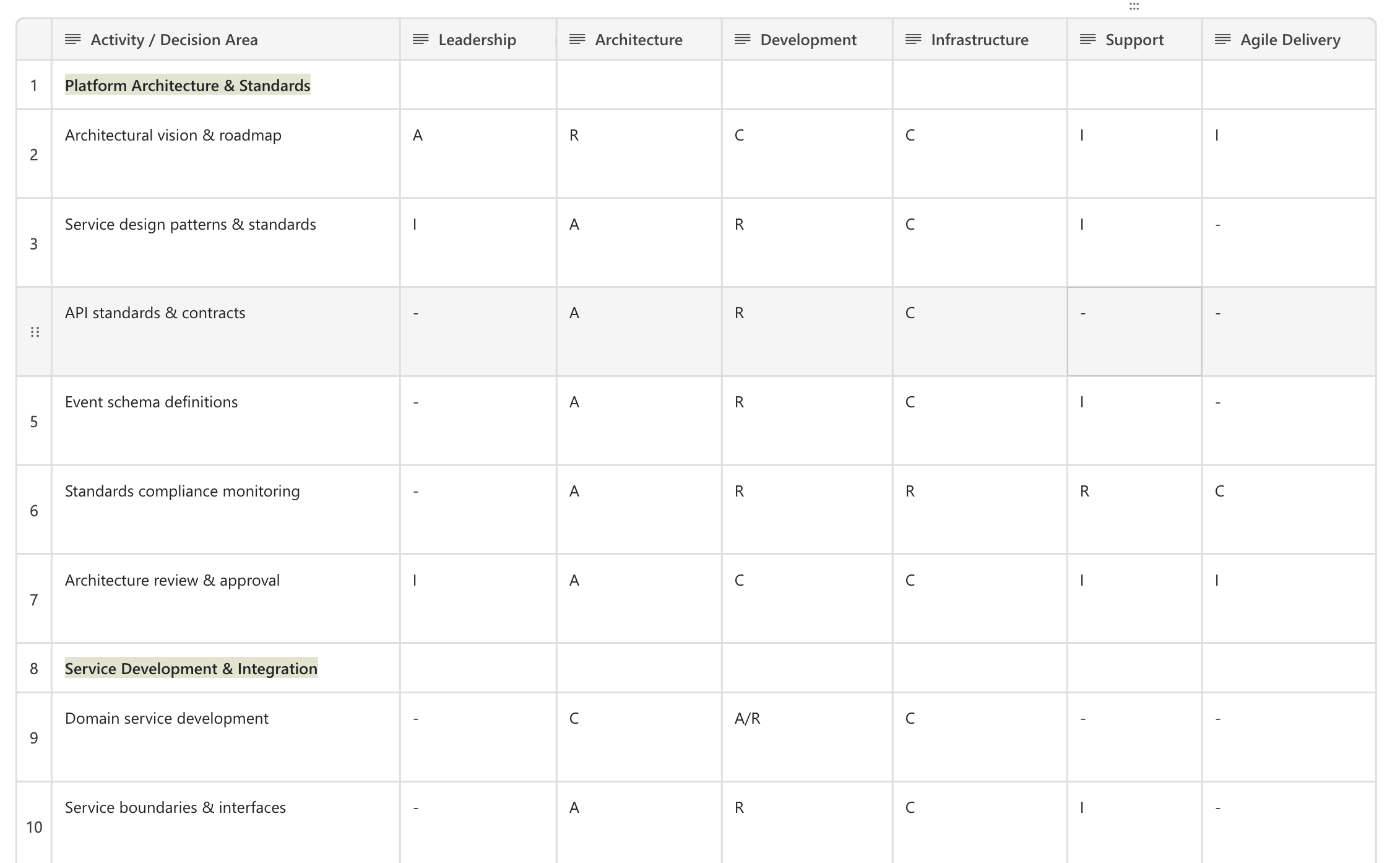
View full IBP Next RACI
#
Implications
The transition to a federated architecture has significant implications across people, processes, technology, and organizational structure. These implications must be carefully planned and managed to ensure successful adoption.
#
1. People/Training
The shift from psuedo micrsoservices to federated architecture requires new skills and competencies across all teams:
Event-Driven Architecture: Teams will need to build competency in Kafka, including understanding topics, partitions, consumer groups, and event ordering guarantees. Developers must learn to design event schemas, handle eventual consistency, and reason about distributed system behavior.
Distributed Systems Patterns: Teams must understand distributed tracing (e.g., OpenTelemetry, Jaeger), correlation IDs, distributed transactions, saga patterns, and idempotency. They need to think about network partitions, split-brain scenarios, and eventual consistency trade-offs.
Schema Management: Teams must adopt schema evolution practices using schema registries (e.g., Apicurio). This includes understanding backward/forward compatibility, schema versioning strategies, and managing breaking changes across service boundaries.
Contract Testing: Consumer-Driven Contracts (CDC) and contract testing tools (e.g., Pact) become essential for ensuring service compatibility without tight coupling. Teams must learn to write and maintain contract tests as part of their CI/CD pipelines.
DevOps Skills: DevOps skills will be essential across all teams due to microservice ownership. Each team must be able to deploy, monitor, and troubleshoot their services independently. This includes understanding containerization, infrastructure as code, and observability tooling.
Governance Understanding: Clear understanding of governance boundaries and RACI responsibilities is critical. Teams must know when they can make autonomous decisions versus when they need Architecture approval. This requires training on the. governance model and regular reinforcement through architecture reviews.
#
2. Process Adjustments
The development and deployment processes must evolve to support independent service development while maintaining platform coherence:
Independent Deployment Pipelines: CI/CD pipelines must support independent deployments, versioning, and rollback strategies. Each service should have its own pipeline that can deploy to production without requiring coordination with other services. This includes blue-green deployments, canary releases, and feature flags.
Contract-Driven Development: CDC (Consumer-Driven Contracts) and schema registries must be adopted. Services must define contracts before implementation, and contract tests must run in CI/CD pipelines to prevent breaking changes from reaching production.
Architecture Review Gates: Architecture review and approval gates for service design and standards compliance must be established. Before a service is implemented, its design must be reviewed by the Architecture team to ensure it follows platform standards, uses appropriate patterns, and aligns with the overall architecture vision.
Compliance Monitoring: Ongoing compliance monitoring and technical debt remediation processes must be implemented. The Architecture team should regularly audit services for compliance with standards, identify technical debt, and work with Development teams to create remediation plans.
Cross-Service Coordination: When services need to coordinate (e.g., for feature releases that span multiple services), processes must be established to manage this coordination without requiring tight coupling. This includes release planning, feature flag coordination, and backward compatibility strategies.
Incident Response: Incident management processes must account for distributed system failures. Teams must understand how to identify which service is failing, how to trace issues across service boundaries, and how to coordinate incident response when multiple services are involved.
#
3. Tooling
The federated architecture requires a comprehensive tooling ecosystem to support development, deployment, monitoring, and governance:
Event Streaming: Apache Kafka (or equivalent) for event-driven communication, with appropriate tooling for topic management, consumer lag monitoring, and schema evolution.
API Gateway: Kong (or equivalent) for centralized API management, including routing, rate limiting, authentication, request transformation, and API versioning.
Observability Stack:
- Metrics: Cloudwatch for metrics collection and alerting
- Logging: Datadog or equivalent for centralized log aggregation
- Tracing: Jaeger or equivalent for distributed tracing
- Dashboards: Cloudwatch or Grafana for visualization and monitoring dashboards
- Alerting: PagerDuty or equivalent for incident notification
Schema Management: Schema registries (Apicurio) for managing event schemas and API contracts with versioning and compatibility checking.
API Documentation: OpenAPI tools for documenting synchronous and asynchronous APIs, enabling contract-first development and automated testing.
Governance Tooling: Standards compliance monitoring tools and architecture review workflows. This may include automated compliance checking (e.g., linting, static analysis), architecture decision records (ADRs) tracking, and service catalog management.
Infrastructure as Code: Terraform modules and templates for consistent infrastructure provisioning across services, with Infrastructure team maintaining core modules and Development teams using them.
#
4. Risks
The federated architecture introduces several risks that must be actively managed:
Platform Service Bottlenecks: Central platform services (e.g., Customer, Auth) risk becoming bottlenecks or single points of failure if not designed for high availability and horizontal scaling. These services must be designed with redundancy, caching, and circuit breakers to prevent cascading failures.
Event Choreography Complexity: Event choreography can become difficult to reason about if not clearly modeled. Without proper documentation and visualization of event flows, understanding system behavior becomes challenging. Teams must maintain event flow diagrams, use distributed tracing, and document event contracts.
Operational Complexity: Operational complexity is higher and requires sophisticated monitoring and incident response. Teams must invest in observability tooling, runbooks, and incident response processes. The distributed nature of the system makes debugging more complex, requiring correlation IDs and distributed tracing.
Governance Friction: Governance friction can occur if Architecture-Development boundaries are not clearly understood or respected. This can manifest as Development teams feeling constrained or Architecture teams becoming bottlenecks. Clear communication, regular architecture office hours, and a collaborative approach to standards evolution are essential.
Data Consistency Challenges: Eventual consistency introduces challenges for workflows that require strong consistency. Teams must understand when eventual consistency is acceptable and when they need to use patterns like sagas or distributed transactions to achieve stronger guarantees.
Service Coupling Through Shared Models: Platform services risk becoming tight coupling points if they expose too much implementation detail or require frequent breaking changes. Careful API design and versioning strategies are essential.
Testing Complexity: Integration testing becomes more complex in a distributed system. Teams must rely on contract testing, local development environments with service mocks, and comprehensive observability to validate system behavior.
#
Trade-Offs
The federated architecture represents significant trade-offs compared to the current approach. Understanding these trade-offs is essential for making informed decisions and managing expectations.
#
Benefits
Improved System Resilience: Fault isolation means that failures in one service do not cascade to others. If a non-critical service fails, the rest of the platform continues operating. This dramatically improves overall system availability compared to monolithic systems where a single bug can bring down the entire platform.
Faster Feature Delivery: Decoupled, autonomous services enable teams to release features independently without waiting for platform-wide releases. Teams can optimize their development practices, release cadence, and technology choices within their service boundaries, leading to faster innovation cycles.
High Scalability: Kafka's partitioned, distributed log model and event-driven communication enable high-throughput processing and independent scaling of services based on their specific load patterns. Services can scale horizontally without affecting others, allowing the platform to handle varying load patterns efficiently.
Team-Architecture Alignment: Better alignment between team structure and architecture (Inverse Conway's Maneuver) reduces coordination overhead and enables teams to work more autonomously. Teams can optimize their processes and technology choices for their specific domain needs.
Technology Diversity: Teams can choose appropriate technology stacks for their specific use cases (e.g., Python for data processing, Go for high-performance services, Java for enterprise integration) without being constrained by a single technology choice for the entire platform.
Easier Maintenance: Changes to one service don't require rebuilding and redeploying the entire platform. This reduces deployment risk and enables more frequent, smaller releases.
#
Drawbacks
Operational Complexity: Steeper operational learning curve and increased complexity. Teams must understand distributed systems concepts, event-driven patterns, and operational practices for distributed systems. This requires investment in training and tooling.
Potential Tight Coupling: Risk of accidental tight coupling through over-centralized platform services. If platform services expose too much implementation detail or require frequent breaking changes, they can become bottlenecks that negate the benefits of decoupling.
Cultural Shift: Requires a cultural and process shift toward observability, event thinking, and contract-first development. Teams must learn to think in terms of events, eventual consistency, and distributed system behavior. This cultural change takes time and requires ongoing reinforcement.
Distributed System Challenges: Introduces challenges around distributed transactions, eventual consistency, and network partitions. Teams must understand when eventual consistency is acceptable and how to handle scenarios where services are temporarily unavailable.
Testing Complexity: Integration testing becomes more complex. Teams must rely on contract testing, service mocks, and comprehensive observability rather than traditional integration tests. Debugging distributed systems is more challenging and requires correlation IDs and distributed tracing.
Initial Investment: Requires significant upfront investment in infrastructure, tooling, and training. The platform must invest in Kafka clusters, observability tooling, CI/CD infrastructure, and training programs before teams can begin building services.
Coordination Overhead: While services can be developed independently, there is still coordination overhead for cross-service features, shared data models, and platform-wide changes. This requires careful management to avoid slowing down delivery.
Data Consistency Trade-offs: Eventual consistency means that some operations may see stale data temporarily. Teams must design their services to handle this, which may require additional complexity in application logic.
#
Key Evaluation Metrics
To measure the success of the federated architecture adoption, we will track the following key metrics:
Independent Deployability: 90% of services independently deployable without cross-team coordination. This metric measures whether teams can release their services on their own cadence without requiring coordination with other teams. It validates that the architecture has achieved sufficient decoupling.
Fault Isolation Effectiveness: <2% production incidents tied to upstream service failures. This measures whether the architecture successfully isolates failures and prevents cascading failures. It validates that services are resilient to failures in other services.
Operational Efficiency: <10 minutes MTTR (Mean Time To Recovery) per service via observability tooling. This measures how quickly teams can identify, diagnose, and resolve issues in their services using the observability stack. It validates that the operational tooling and processes are effective.
Delivery Velocity: 30% faster delivery velocity per team after full migration. This measures whether the federated architecture enables teams to deliver features more quickly. It compares team velocity before and after migration to validate that the architecture achieves its goal of faster innovation.
Event Processing Performance: Kafka consumer lag < 5 seconds on average under normal load. This measures whether the event-driven backbone can handle the platform's event volume without significant delays. It validates that Kafka is effectively supporting the distributed communication needs.
Standards Compliance: >95% of services pass architecture review and compliance checks on first submission. This measures whether teams are effectively following the standards and patterns defined by the Architecture team, reducing rework and ensuring consistency.
Service Availability: Each service achieves >99.9% availability (excluding planned maintenance). This measures whether teams can maintain high availability for their services independently, validating that the distributed architecture doesn't compromise reliability.
Cross-Service Feature Delivery Time: <2 weeks from design approval to production for cross-service features. This measures the coordination overhead for features that span multiple services, ensuring that the federated architecture doesn't introduce excessive coordination delays.
#
Conclusion
We recommend adopting a federated modular architecture to evolve IBP into a scalable, resilient, and innovation-friendly platform. This architectural transformation represents a fundamental shift from a monolithic, tightly coupled system to a distributed, event-driven platform that enables independent service development and deployment.
The approach enables service-level autonomy, promotes independent team velocity, and aligns with best-in-class architecture patterns established by industry leaders. While operational complexity increases compared to a monolithic system, the architectural and organizational benefits - including improved resilience, faster feature delivery, and better scalability - will allow IBP to deliver digital capabilities faster and more reliably.
The governance model, with its clear RACI framework, ensures that autonomy doesn't lead to chaos. By establishing clear accountability and responsibility boundaries, the model enables teams to move quickly within defined standards while maintaining quality, reliability, and consistency across the platform. The Architecture team sets the standards, Development teams implement within those standards, and Infrastructure teams provide the operational foundation - all working together to deliver a cohesive platform experience.
The success of this transformation depends on several factors: comprehensive training to build distributed systems competency, investment in tooling and infrastructure, cultural adoption of event-driven thinking and contract-first development, and ongoing commitment to the governance model. With proper execution, the federated architecture will position IBP to scale with Ricoh's growing digital services needs while maintaining high quality and reliability standards.
This decision sets the foundation for IBP's evolution over the coming years. As the platform matures, we expect to refine patterns, optimize the governance model based on learnings, and continue investing in the tooling and processes that support effective federated development. The architecture is designed to evolve, and we will continuously assess and adjust based on the evaluation metrics and real-world experience.
#
References
- Ricoh DSC - IBP Next Presentation
- RACI for IBP Next
- Designing Data-Intensive Applications by Martin Kleppmann
- Building Evolutionary Architectures by Ford, Parsons, and Kua